
Micro otimizações C#
- Gerson Reis

- 15 de jul. de 2020
- 4 min de leitura
Atualizado: 16 de jul. de 2020

Recentemente precisei mais uma vez transformar uma lista de objetos que eu tinha em um csv e disparar isto por email.
Não sei quantas vezes já fiz isto no meu dia a dia de desenvolvedor. Mas tenho certeza que foram muitas.
Porém desta vez abordei diferente de todas as outras, resolvi que não quero ficar sempre buscando a lógica de montar csv, por mais que seja algo simples, o fato de ser simples, poucas vezes temos tempo de fazer algo bacana, que vá ter a performance que deve ter.
Geralmente concatenamos as colunas, criamos um arquivo .csv e enviamos o email.
Mas muitas das vezes esse csv é criado a partir de uma lista muito grande e assim pagamos pelo custo de criar o mesmo, como estamos manipulando string e listas e fazendo conversões, este processo acaba saindo muito caro para a nossa aplicação.
Sendo assim então resolvi ter uma solução genérica no meu github, para quando eu precisar fazer isto novamente, ter ele feito de uma forma melhor, agora quando precisar já terei onde buscar e tenho certeza de como as coisas funcionam.
A primeira versão fiz algo genérico porém simples, sem se preocupar tanto com a performance, pois primeiro gostaria de ter o csv sendo criado e depois melhorar. A partir de agora vou melhorar isso através de análises com ferramentas de benchmark para ter uma noção do que consigo melhorar. Sendo assim, vou relatar neste artigo o que mudei, e qual resultado isto trouxe através de números!
Ferramenta: BenchmarkDotNet.
É uma ferramenta comum para micro otimizações como esta, porém antes de começar precisamos entender como interpretar a nossa melhoria, certo?
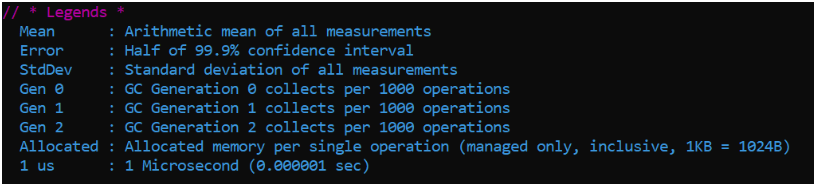
Quando usamos o BenchmarkDotNet com as configurações padrões, ele nos revela algumas colunas como resultado da performance do seus métodos monitorados.
Neste caso vamos focar apenas em duas delas, vamos olhar para a coluna Gen 0 e a coluna Allocated

E essas são as instruções para interpretar cada coluna:
A primeira versão que temos, antes de qualquer melhoria é esta:

Para fazer mais sentido vou lhe explicar rapidamente o que deve ser interpretado da coluna Gen 0.
A coluna contém um número de x coleções por 1000 operações, ou seja resultado = x / 1000. Que neste caso é 58594 / 1000 = 58,594 vamos considerar 58.
Isto significa que o Garbage collector está sendo acionado 58 vezes nesta análise.
Como é um relatório de 10 linhas e 4 colunas, isso é realmente bastante! Porém é o padrão quando se faz sem pensar muito no comportamento da aplicação. Que é muito comum no mercado...
Vimos também que este processo teve uma alocação de 24.84kb de nosso processamento. Mais uma vez, isto é bastante.
Se forem olhar o código sendo alguém que não se preocupa tanto, vai até achar o código bacana, porém não faz ideia do que acontece ali.
Vamos melhorar?
A parte principal do código é esta:

Vamos começar pela chamada do método GetCsvFields()(é um método que retorna um array de PropertyInfo, cada item do array corresponde a uma coluna do objeto.
Mas se parar para analisar, o que usamos do propertyInfo é apenas o atributo Name, para localizar os valores de cada linha mais adiante.
Será que é necessário trazer o objeto inteiro? Será que trazer apenas as propriedades Name que é o que precisamos não vai aliviar um pouco?
Bora testar!
Ele era assim:

E mudei ele para ficar assim:

Em seguida já fiz um novo relatório com benchmarkDotNet para ver o ganho desta micro otimização.

Continha rápida: 4.8828 / 1000 = 48,828 vamos considerar 48.
Então com a nossa primeira micro otimização podemos considerar que:
58 representa 100% do esforço do GC, conseguimos reduzir para 48, ganhamos 10 operações.
Então com uma regra de 3 simples, os números nos apresentam uma economia de 17,24% isto na primeira alteração.
Podemos analisar também que a memória alocada para isto, já reduziu 4kb!
Vamos para a próxima.
Agora vamos fazer algo parecido, ao ver o código, é visível que tem um método sendo chamado para obter a coluna da linha e em sequência tem um método, que retorna o valor a ser impresso em determinada linha e coluna. É o GetColumnPropertyInfo()

Vamos primeiramente fazer a mesma coisa, simplesmente no lugar do PropertyInfo, vamos retornar logo o valor que precisamos, desta forma evitamos mais um objeto inteiro alocado.
Ficou assim:

E com mais esta pequena alteração já temos um ganho muito grande.

Partimos de 24 kb de memória e já estamos em 18, isto com apenas duas melhorias que não levam 5 minutos para fazer.
Acredito que já mostrei como faço para validar se a mudança realmente teve efeito, então agora vou mudar mais coisas e logo volto com um novo resultado lhe explicando o que fiz…
Veja:

Antes estava usando o csvwriter uma dll que encontrei para me auxiliar na escrita, realmente facilitou, escrevi a função em pouco tempo e resolvi o que deveria resolver, afinal o csv estava sendo gerado.
Gosto de pensar da seguinte forma: Como o que acabei de fazer vai estar em constante ação, gerando custos de processamento, vou investir um pouco mais do meu tempo para aliviar a barra para nossas máquinas, a longo prazo o valor investido irá voltar!
Podes conferir o resultado aqui: https://github.com/gerson-reis/object-to-csv/blob/master/TheDevTrack.ObjectToCsv/DateTable.cs
Conseguimos baixar bastante, isto porque com esta nova abordagem procurei usar mais os recursos do C# e evitar um pouco os frameworks e dell de helpers.
Resumo da ópera, do início até este momento olhando para as duas colunas que combinamos no começo do texto, levamos nosso custo de processamento para 1 quinto do que era antes, ou seja estamos economizando 80% dos recursos comparado a versão anterior.
Ações assim em rotinas diárias onde você trabalha pode gerar grandes números para empresa e consequentemente para você, pense nisto e saiba porque está escrevendo cada linha(ou ao menos tente saber).
Acredito que ainda podemos melhorar isto, porém daqui para frente o código ficará de mais baixo nível, para isso buscarei mais informações e em breve escrevo uma continuação deste post, hoje apenas evitamos processo desnecessários.
Antes de qualquer micro otimização certifique-se que as áreas afetadas estão cobertas por testes de unidade.
O intuito deste post é demonstrar como faço para analisar micro otimizações, em breve falaremos mais em como utilizar mais ferramentas de benchmark.
Até!


Comentários